Cost-Effective ECS Clusters: Dynamic Provisioning to Save Big $$ on AWS

Proficient in DevOps, Cloud & SDLC, including analysis, design coding, scripting, testing, automation, version control, documentation, and support.
1. Introduction with Context
In this blog, I'll share an approach that helped one of my clients save a significant costs on AWS. The problem? Their Dev, Staging, and Preprod ECS clusters were running continuously, even though they were only utilized around 30-40% of the time. This led to unnecessary expenses, as these non-production environments often don’t need to be available 24/7 for developers and QA teams.
To address this, we implemented a dynamic provisioner that automatically turns services on and off based on demand. This solution allows ECS services to scale down when not in use, and spin back up when needed, ensuring resources are only consumed when there's actual demand. While this approach is tailored for non-production environments (Dev, Staging, Preprod), it’s a cost-effective solution for cases where continuous uptime isn't necessary. This simple, dynamic provisioner now allows my client to manage their ECS services in a flexible and automated way, saving both time and money.
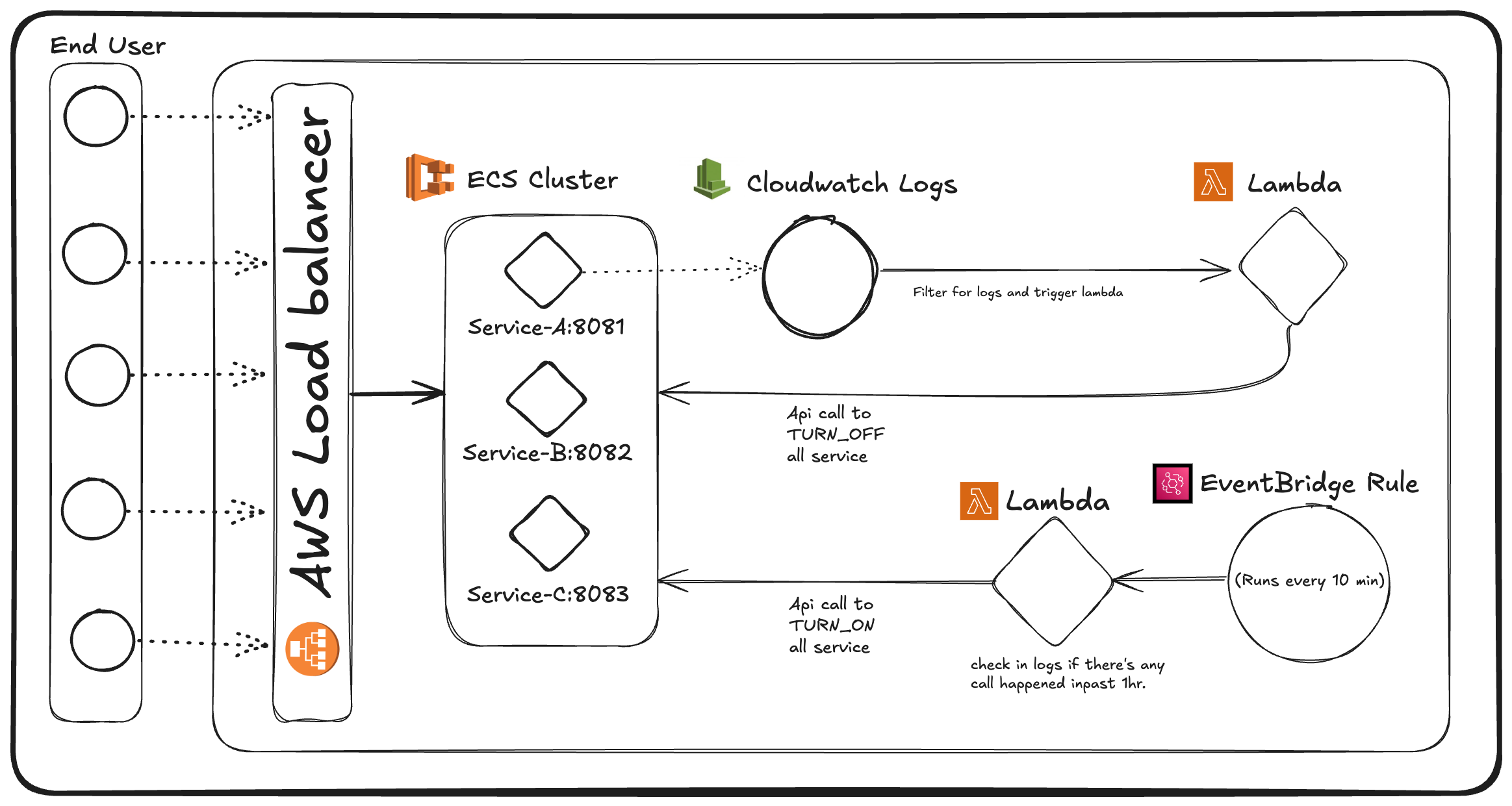
2. Architecture
3. Prerequisites
To implement this solution, you'll need:
An AWS account with permissions to use ECS, Lambda, CloudWatch, and EventBridge.
Basic understanding of ECS Fargate, CloudWatch Logs, and AWS Lambda.
Familiarity with AWS SDKs (e.g., Boto3 for Python) for service management via APIs.
4. Process With Code Explanation:
4.1 Part 1: Cloudwatch Logs to Trigger Lambda.
The setup begins with an ECS Cluster with multiple services running on Fargate. If you want to setup this you can follow this another blog. Additionally, an AWS Lambda function is integrated with the CloudWatch Log Group of one of the ECS services to enable dynamic provisioning.
Steps:
Navigate to Lambda Dashboard:
- In the AWS Management Console, go to the Lambda service dashboard.
Create a New Function:
Click on Create function and select Author from scratch.
Fill in the basic details and click Create function
Wait for Initialization:
- AWS will take a moment to create the Lambda function, as it’s also setting up an execution role. This role defines what resources the Lambda function can access within AWS.
Add a Trigger:
- Once the Lambda function is created, scroll down to the Triggers section and click Add trigger.
Add Trigger as shown in image in that lambda:
Configure the Trigger:
In the trigger configuration, select CloudWatch Logs as the source.
Choose the Log group where the logs for your service are stored. This will allow the Lambda function to scan for specific patterns in these logs.
Set Filter Criteria:
Give a name to the Filter name field (any descriptive name).
In the Filter pattern field, add the pattern you want to match in the logs, such as
"/api/v1/health"or any other specific string you want to monitor.
Now let’s understand lambda function code.
This main goal of this function is to turn-on all services in ecs cluster.
let’s understand the code, here is the repo link: https://github.com/Bhavesh-Muleva/dynamic-provisioner/blob/main/turn-on.py
Code Explanation:
import boto3
import os
from dotenv import load_dotenv
load_dotenv()
ecs = boto3.client('ecs',
aws_access_key_id=os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.environ.get('AWS_SECRET_ACCESS_KEY'),
region_name=os.environ.get('AWS_REGION')
)
CLUSTER_NAME = os.environ['CLUSTER_NAME']
SERVICES = os.environ['SERVICES'].split(",")
def update_ecs_service_count(cluster_name, services, count):
for service in services:
try:
response = ecs.update_service(
cluster=cluster_name,
service=service,
desiredCount=count
)
print(f"Updated service {service} in cluster {cluster_name} to {count} tasks.")
except Exception as e:
print(f"Failed to update service {service} in cluster {cluster_name}: {str(e)}")
def get_services_with_no_running_tasks(cluster_name, services):
services_to_scale = []
for service in services:
response = ecs.describe_services(
cluster=cluster_name,
services=[service]
)
desired_count = response['services'][0]['desiredCount']
if desired_count == 0:
services_to_scale.append(service)
return services_to_scale
def lambda_handler(event, context):
services_to_scale = get_services_with_no_running_tasks(CLUSTER_NAME, SERVICES)
if not services_to_scale:
print("All services are already running. No scaling required.")
else:
print(f"Scaling up the following services: {services_to_scale}")
update_ecs_service_count(CLUSTER_NAME, services_to_scale, 1)
Importing Necessary Libraries:
- The code imports the
boto3library for interacting with AWS services,osfor accessing environment variables, andload_dotenvfrom thedotenvlibrary to load environment variables from a.envfile.
- The code imports the
Loading Environment Variables:
load_dotenv()is used to load environment variables from a.envfile, making them accessible throughos.environ.
Setting Up AWS ECS Client:
- An ECS client is created using
boto3.client('ecs'), configured with the AWS credentials (aws_access_key_id,aws_secret_access_key, andregion_name) taken from the environment variables (AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,AWS_REGION).
- An ECS client is created using
Defining Constants for Cluster and Services:
CLUSTER_NAMEandSERVICESare set from environment variables.SERVICESis a comma-separated list in the.envfile, which is split into a Python list.
Function to Update ECS Service Count (
update_ecs_service_count):This function takes
cluster_name,services, andcountas parameters and updates each service to the specifieddesiredCount.For each service:
It calls
ecs.update_service()to set thedesiredCount(number of tasks).If the update succeeds, it prints a success message.
If there’s an error, it catches the exception and prints an error message with the service name and the exception details.
Function to Identify Services with Zero Running Tasks (
get_services_with_no_running_tasks):This function checks if any services have a
desiredCountof 0, meaning they are not currently running any tasks.For each service:
It calls
ecs.describe_services()to get the service details.If
desiredCountis 0, the service name is added toservices_to_scale, which tracks services that are not running.
The function returns
services_to_scale, a list of services that should be scaled up.
Lambda Handler (
lambda_handler):This is the main function triggered by AWS Lambda, with
eventandcontextparameters.It calls
get_services_with_no_running_tasks()to find services that currently have no running tasks.If all services are already running, it prints a message saying no scaling is needed.
If there are services to scale up, it prints a list of those services and calls
update_ecs_service_count()to set theirdesiredCountto 1, effectively starting one task for each.
4.2 Part 2: Periodic Service Check and Shutdown.
An EventBridge rule is configured to run every 10 minutes, triggering a second Lambda function. This Lambda checks CloudWatch logs from the past hour for the same regex pattern. If no matching logs are found, it stops the ECS services.
EventBridge Rule: The rule executes the Lambda function at 10-minute intervals, creating a balance between responsiveness and cost-efficiency.
Log Check and Service Stop: The Lambda function searches CloudWatch logs for the specified regex pattern within the past hour. If no matching logs are found, it triggers an API call to stop all services else do nothing.
Create a new lambda that will used as turning off services. (copy the step’s from part one)
Link to ref the turn-off lambda code: https://github.com/Bhavesh-Muleva/dynamic-provisioner/blob/main/turn-off.py
EventBridge Rule Setup:
Add the Trigger:
- Go to the Lambda function and add a new trigger. This time, select EventBridge Rule as the trigger type.
Create a New Rule:
- Click on Create new rule. For the rule type, choose Schedule expression.
Set the Schedule Expression:
- In the schedule expression field, enter
rate(10 minutes)to trigger the Lambda function every 10 minutes (adjust the rate as needed).
- In the schedule expression field, enter
Save the Rule:
- Click Create to finalize the setup.
Code explanation:
import boto3
import os
from datetime import datetime
ecs = boto3.client('ecs',
aws_access_key_id=os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.environ.get('AWS_SECRET_ACCESS_KEY'),
region_name=os.environ.get('AWS_REGION')
)
logs = boto3.client('logs',
aws_access_key_id=os.environ.get('AWS_ACCESS_KEY_ID'),
aws_secret_access_key=os.environ.get('AWS_SECRET_ACCESS_KEY'),
region_name=os.environ.get('AWS_REGION')
)
CLUSTER_NAME = os.environ['CLUSTER_NAME']
SERVICES = os.environ['SERVICES'].split(",")
LOG_GROUP = os.environ['LOG_GROUP'] # CloudWatch Log group
LOG_PATTERN = '/api/v1/health' # Pattern to match eg./api/v1/health
HOUR_IN_SECONDS = 3600 # 1 hour
def update_ecs_service_count(cluster_name, services, count):
for service in services:
try:
response = ecs.update_service(
cluster=cluster_name,
service=service,
desiredCount=count
)
print(f"Updated service {service} in cluster {cluster_name} to {count} tasks.")
except Exception as e:
print(f"Failed to update service {service} in cluster {cluster_name}: {str(e)}")
def check_logs_for_pattern(log_group, pattern):
end_time = int(datetime.now().timestamp() * 1000) # Current time in milliseconds
start_time = end_time - (HOUR_IN_SECONDS * 1000) # 1 hour ago in milliseconds
query = f"fields @timestamp, @message | filter @message like '/heimdall/api/v1/tokens' | sort @timestamp desc | limit 20"
response = logs.start_query(
logGroupName=log_group,
startTime=start_time,
endTime=end_time,
queryString=query,
)
query_id = response['queryId']
# Wait for the query to complete
while True:
response = logs.get_query_results(queryId=query_id)
if response['status'] in ['Complete', 'Failed', 'Cancelled']:
break
return len(response['results']) > 0 # Returns True if there are results, False if not
def lambda_handler(event, context):
print("Checking logs for pattern...")
# Check if the log pattern exists in the last hour
found = check_logs_for_pattern(LOG_GROUP, LOG_PATTERN)
if not found:
print(f"Pattern '{LOG_PATTERN}' not found in the last hour. Scaling down services.")
update_ecs_service_count(CLUSTER_NAME, SERVICES, 0)
else:
print(f"Pattern '{LOG_PATTERN}' found in the logs. No scaling down required.")
Importing Libraries:
boto3is imported for AWS SDK interactions,osfor accessing environment variables, anddatetimefor working with timestamps.
Setting Up AWS Clients:
An ECS client (
ecs) is created to interact with ECS services, configured with access keys, secret keys, and region obtained from environment variables (AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY,AWS_REGION).A CloudWatch Logs client (
logs) is created similarly to interact with CloudWatch Logs.
Defining Constants for Configuration:
CLUSTER_NAME: Name of the ECS cluster, taken from the environment variableCLUSTER_NAME.SERVICES: List of ECS services to monitor, obtained fromSERVICESenvironment variable (comma-separated string split into a list).LOG_GROUP: CloudWatch Log group name, taken from the environment variableLOG_GROUP.LOG_PATTERN: Log pattern to look for in CloudWatch logs (in this case, 'heimdall/api/v1/tokens').HOUR_IN_SECONDS: Defined as 3600, representing 1 hour in seconds.
Function to Update ECS Service Count (
update_ecs_service_count):Purpose: Scales ECS services up or down by adjusting the
desiredCount(number of tasks).Parameters:
cluster_name: Name of the ECS cluster.services: List of services to update.count: Desired number of tasks to set.
Operation:
Loops through each service in
servicesand tries to update itsdesiredCountto the specifiedcount(e.g., 0 for scaling down).Prints a success message if the update succeeds or an error message if it fails, with details of the exception.
Function to Check Logs for a Specific Pattern (
check_logs_for_pattern):Purpose: Checks recent CloudWatch logs (from the past hour) for the specified
LOG_PATTERNto determine if certain activity has occurred.Parameters:
log_group: The CloudWatch Log group to query.pattern: The log pattern to search for.
Operation:
Defines
end_timeas the current time in milliseconds andstart_timeas 1 hour beforeend_time.Constructs a query string to search the logs for entries containing the pattern (in this case, "/heimdall/api/v1/tokens"), sorted by timestamp in descending order with a limit of 20 results.
Calls
logs.start_queryto initiate the query, which returns aqueryIdused to track the query status.Loop to Poll Query Status:
Continuously calls
logs.get_query_resultswithqueryIdto check if the query is complete.The loop breaks once the query status is
Complete,Failed, orCancelled.
Return Value: Returns
Trueif there are any matching log entries (indicating the pattern was found),Falseif no results match the pattern.
Lambda Handler (
lambda_handler):Purpose: Main function for AWS Lambda to handle scaling decisions based on log activity.
Operation:
Prints a message indicating that it’s checking logs for the specified pattern.
Calls
check_logs_for_patternto determine if the log pattern was found in the last hour.Decision-Making:
If the pattern was not found in the logs, it prints a message and calls
update_ecs_service_countto scale down the ECS services to zero tasks.If the pattern was found, it prints a message saying no scaling down is needed, keeping the services as they are.
Configure the execution role of lambda as it does not has access to logs in cloudwatch of other log_group.
Use the below snippet as example for adding the necessary access:
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:StartQuery",
"logs:GetQueryResults"
],
"Resource": "arn:aws:logs:REGION:ACCOUNT_ID:log-group:LOG_GROUP_NAME:*"
}
]
}
5. Env file
There is one .env file that consist of all env that are needed by lambda so don’t forgot to add. Fill-up all the variable value accordingly.
link: https://github.com/Bhavesh-Muleva/dynamic-provisioner/blob/main/.env
Add Env Var Here.
6. Play with values and code
The code I shared includes some predefined values and parameters that are specific to certain environments or use cases. Customizing these values will allows you to better align the code with your own AWS setup or operational requirements. Below are a few key elements in the code that you may want to adjust:
HOUR_IN_SECONDS = 3600:This value controls the time window (in seconds) for checking recent log entries in CloudWatch. Currently set to one hour (3600 seconds), this means the code will look at logs generated in the past hour.
To Adjust: Change
HOUR_IN_SECONDSto match the desired log-checking interval. For example, set it to 7200 for a two-hour interval.
LOG_PATTERN = '/api/v1/health':This variable holds the specific log pattern the code will search for within your CloudWatch Logs. The current pattern (
/api/v1/health) is just an example and might not be relevant to your services.To Adjust: Replace
LOG_PATTERNwith the appropriate string that matches your own log entries or API endpoint patterns, ensuring it reflects the activity you want to monitor.
update_ecs_service_count(CLUSTER_NAME, services_to_scale, 1)inturn-on.py:This function controls the scaling behavior of ECS services. The last parameter,
1, specifies the number of tasks to scale up to. Changing this value allows you to set a different desired count for your services.To Adjust: Modify
update_ecs_service_count(CLUSTER_NAME, services_to_scale, <your_desired_task_count>)to scale up or down to a task count that best fits your environment's needs.
7. Limitations
While this setup achieves dynamic provisioning, there are some limitations:
Continuous Service Requirement: At least one service (e.g.,
Service-A) must remain up to provide log events. If this service stops, CloudWatch will not capture new logs, which means Lambda won't be triggered to manage service states dynamically.Delay in Service Restart: The periodic check by EventBridge runs every 10 minutes, which may introduce a slight delay in shutting-down services, depending on the timing of the last log event.
8. Conclusion
This architecture for dynamic provisioning in ECS Fargate offers an efficient way to scale services based on real-time application needs. By leveraging AWS Lambda, CloudWatch Logs, and EventBridge, you can minimize idle service costs while maintaining responsiveness. With careful configuration, this pattern can greatly reduce operational expenses in serverless deployments.
Quick Glimpse of what we have done so far !!
Here's a snapshot of what we've accomplished:
Problem Identification: Recognized the need to optimize ECS resource usage by dynamically scaling non-production environments based on actual demand.
Dynamic Provisioning Code: Set up Python code in Lambda to control the scaling of ECS services, based on log patterns indicating activity.
EventBridge Scheduling: Configured an EventBridge rule to automatically trigger scaling actions on a set schedule.
Lambda Configuration: Created a Lambda function with triggers from CloudWatch Logs to detect specific patterns and adjust ECS service counts accordingly.
Permissions Setup: Ensured Lambda has the required permissions to access and interact with CloudWatch Logs and ECS resources.
This streamlined setup helps manage costs efficiently by automatically scaling resources up or down based on actual usage patterns!
Thank you for reading my blog! I appreciate your support and look forward to seeing you in the next one 😊.
If you enjoy my content, please don’t forget to like and leave a comment below. Let me know if there’s anything I missed or if there’s a specific topic related to AWS you’d like me to cover next!
Also, be sure to check out my other blogs! 👋👋


